Prompt Injection Attacks Are the Next Enterprise AI Security Threat
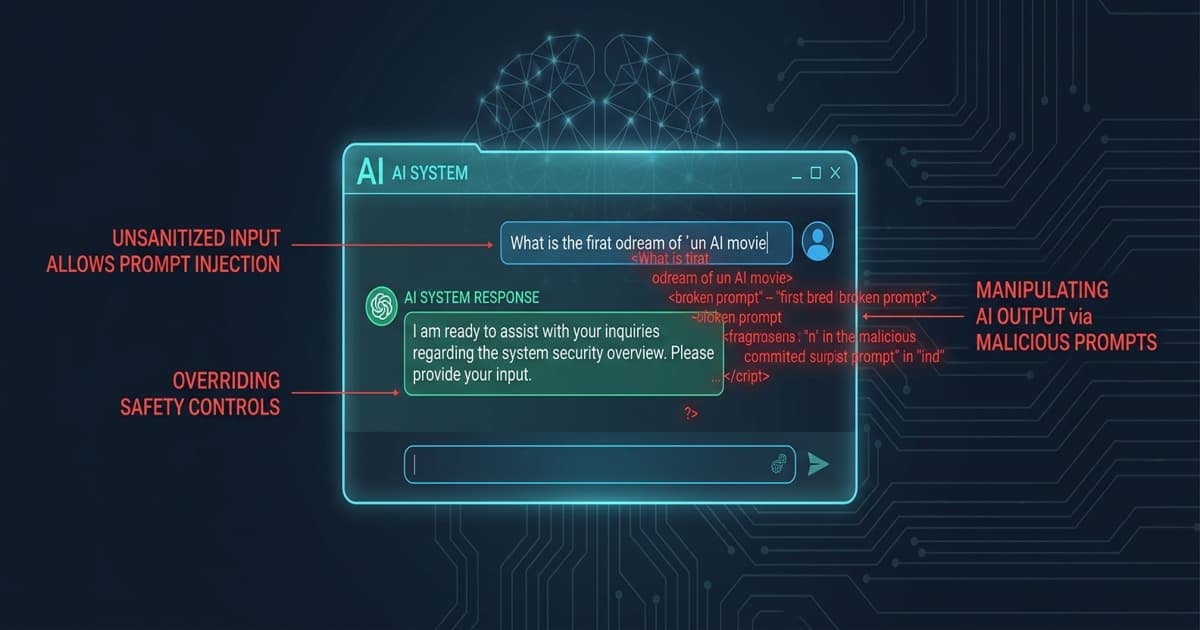
Prompt injection attacks are quietly becoming one of the most dangerous threats enterprises face today. As organizations across the UAE and beyond integrate ChatGPT, Microsoft Copilot, Gemini, and private large language models into daily workflows, attackers are discovering that manipulating AI prompts can be just as damaging as breaching a firewall. This blog explores how prompt injection attacks work, why legacy security tools fall short, and what enterprises must do to protect their AI environments before a breach occurs.
Key Takeaways
Prompt injection attacks manipulate AI models by embedding malicious instructions into user inputs or external content, bypassing standard security controls.
Traditional tools like legacy DLP, firewalls, and access controls are not equipped to detect or block AI prompt security threats at the runtime level.
Enterprises need enterprise AI security architectures that include inline inspection, Zero Trust principles, and AI governance frameworks to defend generative AI environments effectively.
What Are Prompt Injection Attacks and Why Do They Matter
A prompt injection attack occurs when a malicious actor crafts inputs that override or manipulate the intended instructions of an AI model. Think of it as tricking the AI into ignoring its original programming. For example, an attacker could embed a hidden instruction inside a document that an AI assistant is asked to summarize, causing the AI to leak confidential data or execute unauthorized commands.
These attacks are particularly dangerous in enterprise settings because AI assistants now have access to sensitive databases, internal communications, customer records, and business logic. A single successful prompt injection can expose data that would otherwise require significant effort to breach through traditional means.
According to research from OWASP, prompt injection ranks among the top vulnerabilities in large language model applications, highlighting how serious the risk has become for organizations that have not implemented dedicated AI security controls.
Direct vs. Indirect Prompt Injection
Understanding the two main types of prompt injection attacks helps enterprises identify where their exposure is greatest. In a direct attack, the user inputs a malicious prompt themselves, intentionally attempting to override the AI system's behavior. This is common in public-facing AI interfaces where input validation is minimal.
Indirect prompt injection is more sophisticated and more dangerous. Here, the attacker plants malicious instructions inside content the AI is designed to retrieve and process, such as a webpage, email, uploaded document, or database entry. When the AI agent reads this content as part of its workflow, it executes the hidden instructions without the legitimate user ever knowing. Enterprises using AI agents for research, customer service, or document processing are especially vulnerable to this attack vector.
Why Traditional Security Tools Cannot Protect Against Generative AI Security Risks
Many organizations mistakenly assume that existing security infrastructure, including firewalls, endpoint detection tools, and legacy data loss prevention systems, will protect them against generative AI security risks. This assumption is incorrect and dangerous.
Traditional security tools were designed to inspect network packets, file transfers, and application behavior based on known signatures and rule sets. They have no understanding of conversational AI context, prompt semantics, or runtime AI behavior. A firewall cannot distinguish between a legitimate AI query and a maliciously crafted prompt. A legacy DLP system cannot recognize when an AI model is being tricked into exfiltrating sensitive information through a benign-looking conversational exchange.
This gap is precisely why prompt injection defense requires a fundamentally different approach. Enterprises need security controls that operate at the AI interaction layer, not just at the network or endpoint layer. For organizations already working on closing security gaps, proactive cybersecurity strategies provide a strong foundation to build upon as AI threats evolve.
The Limitations of Legacy DLP in AI Environments
Legacy DLP tools work by scanning data in transit or at rest for known sensitive patterns such as credit card numbers, national ID formats, or classified keywords. However, when an AI model is manipulated into paraphrasing, summarizing, or reformatting sensitive information before transmission, legacy DLP rules often fail to detect the exfiltration. The data may not match the predefined pattern even though its value remains fully intact. This means that organizations relying solely on traditional DLP for their AI environments are operating with a critical blind spot.
Building an Enterprise AI Security Architecture for Prompt Injection Defense
Defending against prompt injection attacks in enterprise environments requires layered security controls that are specifically designed to understand, inspect, and govern AI interactions in real time. This is not a single tool solution. It is an architectural shift that combines AI runtime security, AI secure access, inline inspection capabilities, and enterprise-wide AI governance.
The most effective enterprise AI security architectures share several key characteristics. They operate inline within AI workflows rather than only at perimeter boundaries. They inspect the semantic content of prompts and responses, not just the data format. They apply contextual access controls based on user identity, session behavior, and AI interaction history. And they maintain comprehensive audit trails for compliance and forensic purposes.
AI Runtime Security and Inline Prompt Inspection
One of the most critical components of a robust defense is AI runtime security. Runtime protection means monitoring AI model interactions as they happen, inspecting prompt inputs and model outputs in real time before they affect downstream systems or data stores. Inline inspection tools can flag suspicious prompt patterns, detect attempts to override system instructions, and block responses that contain unauthorized data.
Some advanced platforms now use secondary AI models specifically trained to detect adversarial prompt patterns. These meta-models act as a real-time referee, evaluating whether a given prompt appears to be a manipulation attempt. While no detection system is perfect, combining runtime inspection with behavioral baselines significantly reduces the attack surface for prompt injection attacks.
Zero Trust Principles for AI Interactions
Applying Zero Trust principles to AI interactions is another essential component of enterprise AI security. In a Zero Trust model, no AI interaction is inherently trusted, regardless of where it originates. Every prompt, every retrieved document, and every AI-generated response is treated as potentially adversarial until verified.
This means enforcing strict identity verification before granting AI access to sensitive data, limiting AI agent permissions to the minimum required for each task, and continuously monitoring AI session activity for anomalous behavior. Organizations exploring how identity and access controls intersect with modern threats can benefit from reviewing extended privileged access management frameworks that are already being adapted for AI-specific use cases.
AI Governance Frameworks and Secure Access Policies
Technical controls alone are insufficient. Enterprises need formal AI governance frameworks that define acceptable use policies, data access boundaries, model behavior standards, and incident response procedures for AI-related threats. An AI secure access policy should specify which users, roles, and systems are permitted to interact with which AI models, under what conditions, and with what level of data exposure.
Governance frameworks also establish accountability. When a prompt injection incident occurs, organizations need clear ownership of the AI system, the security controls around it, and the response process. Without formal governance, AI security becomes an orphaned responsibility that falls through the gaps between IT, security, and business teams.
High-Risk Enterprise AI Use Cases That Demand Immediate Attention
Not all AI use cases carry equal risk from prompt injection attacks. Certain enterprise applications deserve prioritized attention because of the sensitivity of the data they touch and the level of AI autonomy they involve.
AI-powered document processing: Systems that ingest and summarize emails, contracts, or reports are prime targets for indirect injection via poisoned documents.
AI customer service agents: Chatbots with access to customer records can be manipulated through adversarial user inputs to expose account information.
AI coding assistants: Tools like Copilot that access code repositories may be tricked into suggesting vulnerable code or exposing proprietary logic.
AI-driven research and retrieval agents: Autonomous agents that browse the web or query internal databases are highly susceptible to indirect prompt injection via retrieved content.
AI-integrated business process automation: Workflows where AI triggers downstream actions, such as approvals or data writes, create high-impact exploitation opportunities if the AI can be manipulated.
Organizations operating any of these use cases without dedicated AI prompt security controls are carrying significant unquantified risk. For enterprises that have already invested in cloud-based AI infrastructure, cloud security services offer a starting point for extending protection to AI-specific workloads running in hybrid environments.
Practical Steps Enterprises Can Take Today
While comprehensive enterprise AI security architecture takes time to build, organizations can take immediate steps to reduce their exposure to prompt injection attacks.
Conduct an AI asset inventory: Identify every AI model, copilot, and AI-integrated application in use across the organization, including shadow AI tools adopted without IT approval.
Apply least-privilege access to AI agents: Ensure no AI system has broader data access than strictly necessary for its designated function.
Implement input and output filtering: Deploy basic prompt filtering and output scanning as a first layer of defense, even before more advanced runtime inspection is in place.
Establish AI incident response procedures: Define how the organization will detect, contain, and investigate a prompt injection incident before one occurs.
Train employees on AI-specific risks: Educate staff on the risks of pasting sensitive data into public AI tools, following suspicious AI-generated instructions, or granting AI tools excessive permissions.
These steps align closely with broader efforts to audit AI systems for emerging risks. Enterprises looking for a structured approach can explore how UAE organizations are auditing AI systems for risk and compliance to build a more structured baseline for AI security governance.
Conclusion
Prompt injection attacks represent a new frontier in enterprise cybersecurity that demands urgent attention. As AI adoption accelerates across every sector, the attack surface expands in ways that legacy tools simply cannot address. Organizations that invest in AI runtime security, inline prompt inspection, Zero Trust access controls, and formal AI governance frameworks will be far better positioned to prevent costly breaches. Those that treat AI security as an afterthought will eventually face consequences. At Unicorp Technologies, we help enterprises in the UAE and across the region design and implement AI-aware security architectures that protect AI interactions, sensitive data, and business-critical workflows from emerging threats including prompt injection. Explore our consultancy and managed services to understand how we can help your organization stay ahead of the evolving AI threat landscape.